第十四章 高级IO
非阻塞IO
系统调用可分成两类:“低速”系统调用和其他。低速系统调用是可能会使进程永远阻塞的一类系统调用,包括
- 如果某些文件类型(如读管道、终端设备和网络设备)的数据并不存在,读操作可能会使调用者永远阻塞
- 如果数据不能被相同的文件类型立即接受(如管道中无空间,网络流控制),写操作可能会使调用者永远阻塞
- 在某种条件发生之前打开某些文件类型可能会发生阻塞(如要打开一个终端设备,需要先等待与之连接的调制解调器应答,又如若以只读模式打开FIFO,那么在没有其他进程已用读模式打开该FIFO时也要等待)
- 对已经加上强制性记录锁的文件进行读写
- 某些ioctl操作
- 某些进程间通信函数
虽然读写磁盘文件会暂时阻塞调用者,但并不能将与磁盘IO有关的系统调用视为“低速”
非阻塞IO使我们可以发出open、read和write这样的IO操作,并使这些操作不会永远阻塞。如果这种操作不能完成,则调用立即出错返回,表示该操作如继续执行将阻塞。设置阻塞方法如下
- 如果调用open获得描述符,则可指定O_NONBLOCK标志
- 对于已经打开的一个描述符,则可调用fcntl,由该函数打开O_NONBLOCK文件状态标志。
记录锁
记录锁(record locking)的功能是:当一个进程正在读或修改文件的某个部分时,使用记录锁可以阻止其他进程修改同一文件区。对于UNIX系统而言,“记录”这个词是一个误用,因为UNIX系统内核根本没有使用文件记录这个概念。一个更适合的术语可能是字节范围锁(byte-range locking),因为它锁定的只是文件中的一个区域(也可能是整个文件)
POSIX.1使用fcntl来创建记录锁
1 |
|
对于记录锁,cmd是F_GETLK、F_SETLK或F_SETLKW。第三个参数(我们将调用flockptr)是一个指向flock结构的指针
1 | struct flock { |
- 进程的ID(l_pid)持有的锁能阻塞当前进程(仅有F_GETLK返回)
- 锁可以在当前文件尾端处开始或者越过尾端处开始,但是不能在文件起始位置之前开始
- 如若l_len为0,则表示锁的范围可以扩展到最大可能偏移量。这意味着不管向该文件中追加写了多少数据,它们都可以处于锁的范围内(不必猜测会有多少字节被追加写到了文件之后),而且起始位置可以是文件中的任意一个位置
- 为了对整个文件加锁,我们设置l_start和l_whence指向文件的起始位置,并且指定长度(l_len)为0
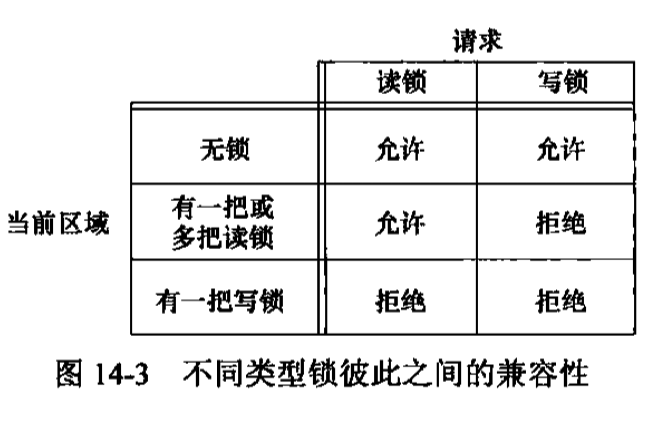
上述兼容性规则适用于不同进程提出的锁请求,并不适用于单个进程提出的多个锁请求。如果一个进程对一个文件区间已经有了一把锁,后来该进程又企图在同一文件区间再加一把锁,那么新锁将替换已有锁。加读锁时,该描述符必须是读打开的。加写锁时,该描述符必须是写打开的
fcntl的三个命令如下
- F_GETLK:判断由flockptr所描述的锁是否会被另外一把锁所排斥(阻塞)。如果存在一把锁,它阻止创建由flockptr所描述的锁,则该现有锁的信息将重写flockptr指向的信息。如果不存在这种情况,则除了将l_type设置为F_UNLCK之外,flockptr所指向结构中的其他信息保持不变
- F_SETLK:设置由flockptr所描述的锁。如果我们试图获得一把读锁(l_type为F_RDLCK)或写锁(l_type为F_WRLCK),而兼容性规则阻止系统给我们这把锁,那么fcntl会立即出错返回,此时errno设置为EACCES或EAGAIN。此命令也用来清除由flockptr指定的锁(l_type为F_UNLCK)
- F_SETLKW:这个命令是F_SETLK的阻塞版本,W表示wait。如果锁请求的读锁或写锁因另一个进程当前已经对所请求区域的某部分进行了加锁而不能被授予,那么调用进程会被设置为休眠。如果请求创建的锁已经可用,或者休眠由信号中断,则该进程被唤醒
应当了解,用F_GETLK测试能否建立一把锁,然后用F_SETLK或F_SETLKW企图建立那把锁,这两者不是一个原子操作。因此不能保证在这两次fcntl调用之间会不会有另一个进程插入并建立一把相同的锁。如果不希望在等待锁变为可用时产生阻塞,就必须处理由F_SETLK返回的可能的出错
在设置或释放文件上的一把锁时,系统按要求组合或分裂相邻区。
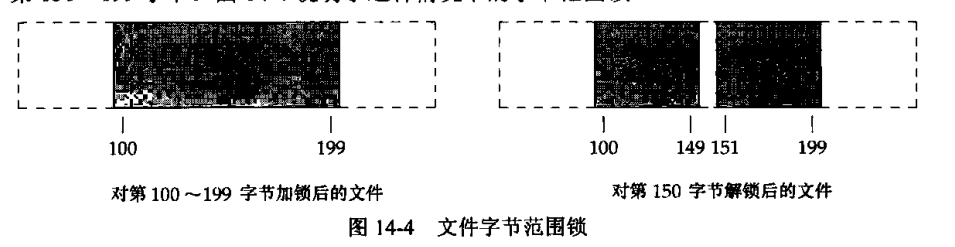
由于F_GETLK命令返回是否有现有的锁阻止调用进程设置它自己的锁。因为F_SETLK和F_SETLKW命令总是替换调用进程现有的锁(若已存在),所以调用进程决不会阻塞在自己持有的锁上,于是,F_GETLK命令决不会报告调用进程自己持有的锁
如果两个进程互相等待对方持有并且不释放(锁定)的资源时,则这两个进程就处于死锁状态。检测到死锁时,内核必须选择一个进程接收出错返回。
锁的隐含继承和释放
- 锁与进程和文件两者相关联。第一,当一个进程终止时,它所建立的锁全部释放;第二,无论一个描述符何时关闭,该进程通过这一描述符所引用的文件上的任何一把锁都会释放(这些锁都是该进程设置的)
1 | // close(fd2)之后,在fd1上设置的锁被释放 |
- 由fork产生的子进程不继承父进程锁设置的锁。这意味着,若一个进程得到一把锁,然后调用fork,那么对于父进程获得的锁而言,子进程被视为另一个进程。对于通过fork从父进程处继承过来的描述符,子进程需要调用fcntl才能获取它自己的锁。这个约束是有道理的,因为锁的作用是阻止多个进程同时写同一个文件。如果子进程通过fork继承父进程的锁,则父进程和子进程就可以同时写同一个文件
- 在执行exec后,新程序可以继承原执行程序的锁。但是注意,如果对一个文件描述符设置执行时关闭标志,那么当作为exec的一部分关闭该文件描述符时,将释放相应文件的所有锁
记录锁的实现
1 | fd1 = open(pathname, ...); |
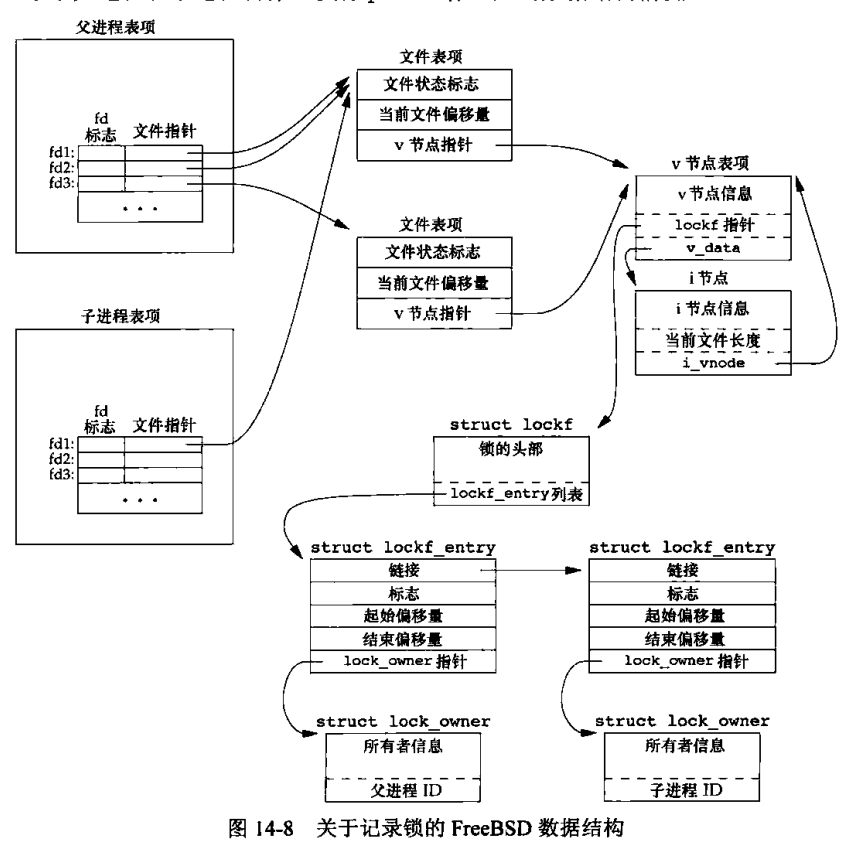
在v节点上有lockf结构,lockf结构描述了一个给定进程的一个加锁区域。关闭描述符时,内核会从该描述符所关联的i节点开始,逐个检查lockf链表中的各项,并释放由调用进程持有的各把锁。内核并不清楚(也不关心)是又哪一个描述符来设置的这把锁
在文件尾端加锁
在对相对于文件尾端的字节范围加锁或解锁时需要特别小心。因为内核必须独立于当前文件偏移量或文件尾端而记住锁。
建议性锁和强制性锁
强制性锁会让内核检查每一个open、read和write,验证调用进程是否违背了正在访问的文件上的某一把锁。对一个特定文件打开其设置组ID位,关闭其组执行位便开启了对该文件的强制性锁机制。因为当组执行位关闭时,设置组ID位不再有意义。
强制性锁对unlink函数没有影响。因此可以删除原文件(已加强制性记录锁),然后将临时文件名改为原文件名。
IO多路复用
IO多路复用,一般是需要构造一张我们感兴趣的描述符(通常都不止一个)的列表,然后调用一个函数,直到这些描述符中的一个已准备好几下IO时,该函数才返回。poll、pselect和select来完成这个工作,从这些函数返回时,进程会被告知哪些描述符已经准备好可以进行IO
函数select和pselect
传给select的参数告诉内核
- 我们所关心的描述符
- 对于每个描述符我们所关心的条件(读、写和异常条件)
- 愿意等待多长时间(可以永远等待、等待一个固定的时间或根本不等待)
从select返回时,内核告诉我们
- 已准备好描述符的数量
- 对于读、写或异常这3个条件中的每一个,哪些描述符已准备好
使用这种返回信息,就可以调用相应的IO函数(read或write),并且确知该函数不会阻塞
1 |
|
tvptr指定愿意等待的时间长度,单位是秒和微秒。可以指定永远等待、不等待或等待指定的时间
中间3个参数是指向描述符集的指针。分别指明读、写或异常条件的描述符集合。如果不关心相应条件,可以将参数设置为NULL,如果3个指针都为NULL,则select提供了精度更高的定时器
fd_set可以认为是一个bitmap。需要通过以下函数来进行操作
1 |
|
这些接口可以实现为宏或函数
maxfdp1的意思是最大文件描述符编号值加1。考虑所有3个描述符集,在3个描述符集中找出最大描述符编号值,然后加1,这就是第一个参数值。也可以将其设置为FD_SETSIZE,这是一个常量,指定最大描述符数,通常是1024。
返回值
- 返回-1表示出错
- 返回0表示没有描述符准备好。此时,所有的描述符集都会置0
- 一个正返回值说明了已经准备好的描述符数。该值是3个描述符中已准备好的描述符数之和,所以如果同一描述符已准备好读和写,那么在返回值中会对其计数两次。在这种情况下,3个描述符集中仍旧打开的位对应于已准备好的描述符
准备好含义如下
- 对于读,是进行read操作不会阻塞
- 对于写,是进行write操作不会阻塞
- 对于异常条件,是描述符有一个未决异常条件。包括:在网络连接上到达带外数据,或者在处于数据包模式的伪终端上发生了某些条件
- 对于读、写和异常条件,普通文件的文件描述符总是返回准备好
一个描述符阻塞与否并不影响select是否阻塞。如果在一个描述符上碰到了文件尾端,则select会认为该描述符是可读的。然后调用read,它返回0,这是UNIX系统指示到达文件尾端的方法(很多人错误的认为,到达文件尾端时,select会指示一个异常条件)
除以下几点外,pselect与select相同
- select的超时值用timeval结构指定,但pselect使用timespec结构
- pselect的超时值被声明为const,这就保证调用pselect不会改变此值,而select可能改变此值(取决于实现,如Linux 3.2.0将用剩余时间值更新该结构)
- pselect可使用可选的信号屏蔽字。若sigmask为NULL,则在信号有关的方面,pselect与select相同。否则sigmask指定信号屏蔽字,在调用pselect时,以原子操作的方式安装该信号屏蔽字。在返回时,恢复以前的信号屏蔽字
函数poll
poll函数类似select,但是程序员接口有所不同。poll函数可用于任何类型的文件描述符
1 |
|
与select不同,poll不是为每个条件构造一个描述符集,而是构造一个pollfd结构的数组,每个数组元素指定一个描述符编号以及我们对该描述符感兴趣的条件
1 | struct pollfd { |
应将每个数组元素的events成员设置为以下值的一个或几个,通过这些值告诉内核我们关心的是每个描述符的哪些事件。返回值revents成员由内核设置,用于说明每个描述符发生了哪些事件。poll不更改events成员

当一个描述符被挂断(POLLHUP)后,就不能再写该描述符,但是有可能仍然可以从该描述符读取到数据
timeout参数指定我们愿意等待多长时间。
理解文件尾端与挂断之间的区别是很重要的。如果我们正从终端输入数据,并键入文件结束符,那么就会打开POLLIN,于是我们就可以读文件结束指示(read返回0)。revents中的POLLHUP没有打开。如果正在调制解调器,并且电话线已挂断,我们将街道POLLHUP通知
与select一样,一个描述符是否阻塞不会影响poll是否阻塞
函数readv和writev
readv和writev函数用于在一次函数调用中读、写多个非连续缓冲区。有时也将这两个函数称为散布读(scatter read)和聚集写(gather write)
1 |
|
iovec结构如下
1 | struct iovec { |
iov数组中的元素数由iovcnt指定,其最大值受限于IOV_MAX。writev函数从缓冲区中聚集输出数据的顺序是:iov[0]、iov[1]直至iov[iovcnt-1]。writev返回输出的总字节数,通常应等于所有缓冲区长度之和
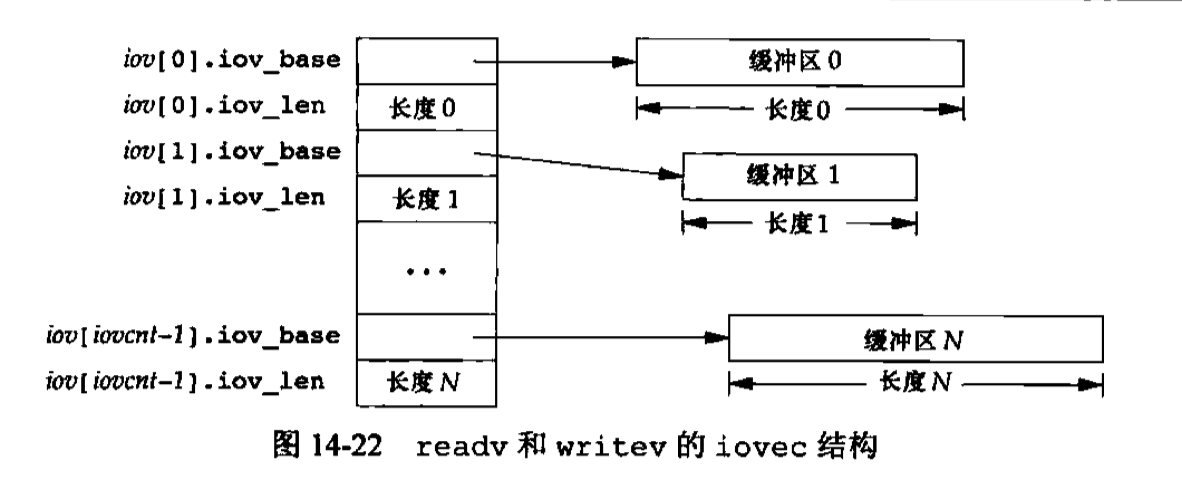
readv函数则将读入的数据按上述同样顺序散布到缓冲区中。readv总是先填满一个缓冲区,然后再填写下一个。readv返回读到的字节总数。如果遇到文件尾端,已无数据可读,则返回0
应当用尽量少的系统调用次数来完成任务。如果我们只写少量的数据,将会发现自己复制数据然后使用一次write会比用writev更合算。但也可能发现,我们管理自己的分段缓冲区会增加程序额外的复杂性成本,所以从性能成本的角度来看不合算
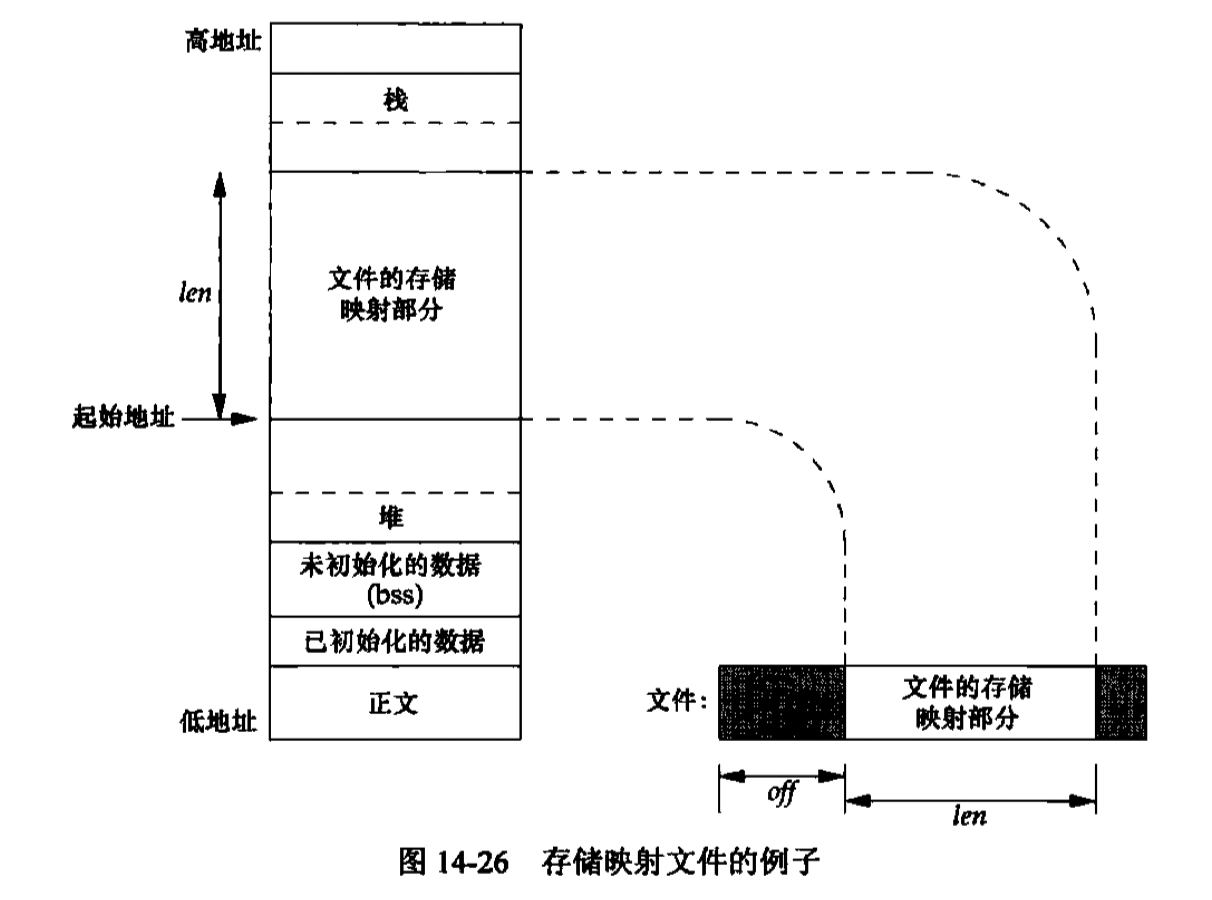
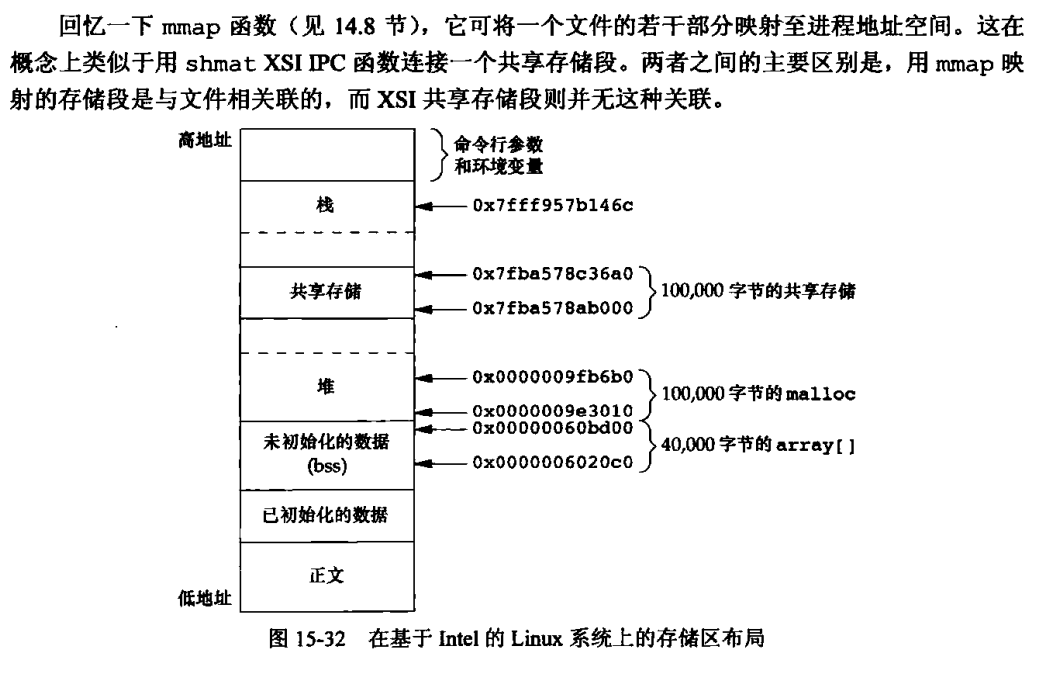
存储映射IO
存储映射IO(memory-mapped IO)能将一个磁盘文件映射到存储空间中的一个缓冲区上,于是,当从缓冲区中取数据时,就相当于读文件中的相应字节。与此类似,将数据存入缓冲区时,相应字节就自动写入文件。这样就可以在不使用read和write的情况下执行IO
为了使用这一功能,应首先告诉内核将一个给定的文件映射到一个存储区域中。这是由mmap函数实现的
1 |
|
addr参数用于指定映射存储区的起始位置。通常将其设置为0,这表示由系统选择该映射区的起始地址。此函数的返回值是该映射区的起始地址
fd参数是指定要被映射文件的描述符。在文件映射到地址空间之前,必须先打开该文件。len参数是映射的字节数,off是要映射字节在文件中的起始偏移量
prot参数指定了映射存储区的保护要求
- PROT_READ:映射区可读
- PROT_WRITE:映射区可写
- PROT_EXEC:映射区可执行
- PROT_NONE:映射区不可访问
可将参数prot指定为PROT_NONE,也可以指定为PROT_READ、PROT_WRITE和PROT_EXEC的任意组合的按位或。对指定映射存储区的保护要求不能超过文件open模式访问权限。例如,若该文件是只读打开的,那么对映射存储区就不能指定PROT_WRITE
映射存储区一般位于堆和栈之间:这属于实现细节,各种实现之间可能不同
flag参数如下
- MAP_FIXED:返回值必须等于addr。因为这不利于可移植性,所以不鼓励使用此标志。如果未指定此标志,而且addr非0,则内核只把addr视为在何处设置映射区的一种建议,但是不保证会使用所要求的地址。将addr指定为0可获得最大可移植性
- MAP_SHARED:这一标志描述了本进程对映射区所进行的存储操作的配置。此标志指定存储操作修改映射文件,也就是,存储操作相当于对该文件的write。必须指定本标志或下一个标志(MAP_PRIVATE),但不能同时指定两者
- MAP_PRIVATE:本标志说明,对映射区的存储操作导致创建该映射文件的一个私有副本。所有后来对该映射区的引用都是引用该副本。(此标志的一种用途是用于调试程序,它将程序文件的正文部分映射至存储区,但允许用户修改其中的指令。任何修改值影响程序文件的副本,而不影响原文件)
每种实现都可能还有另外一些MAP_XXX标志值,它们是那种实现所特有的。详细情况清参考手册
off的值和addr的值(如果指定了MAP_FIXED)通常被要求是系统虚拟存储页长度的倍数。虚拟存储页长可用带参数_SC_PAGESIZE或_SC_PAGE_SIZE的sysconf函数得到。因为off和addr常常指定为0,所以这种要求一般并不重要
既然映射文件的起始偏移量受系统虚拟存储页长度的限制,那么如果映射区的长度不是页长度的整数倍时,会怎么样呢?假定文件长度为12字节,系统页长为512字节,则系统通常提供512字节的映射区,其中后500字节被设置为0。可以修改后面的这500字节,但任何改动都不会在文件中反映出来。于是不能用mmap将数据添加到文件中。我们必须先加长该文件
与映射区相关的信号有SIGSEGV和SIGBUS。信号SIGSEGV通常用于指示进程试图访问对它不可用的存储区。如果映射存储区被mmap指定成了只读的,那么进程试图将数据存入这个映射存储区的时候,也会产生此信号。如果映射区的某个部分在访问时已不存在,则产生SIGBUS信号。例如,假设用文件长度映射了一个文件,但在引用该映射区之前,另一个进程已将该文件截断。此时,如果进程试图访问对应于该文件已截去部分的映射区,将会接收到SIGBUS信号
子进程能通过fork继承存储映射区(因为子进程复制父进程地址空间,而存储映射区是该地址空间中的一部分),但是由于同样的原因,新程序则不能通过exec继承存储映射区
调用mprotect可以更改一个现有映射的权限
1 |
|
prot的合法值与mmap中的prot参数一样。请注意,地址参数addr的值必须是系统页长的整数倍
如果修改的页是通过MAP_SHARED标志映射到地址空间的,那么修改不会立即写回到文件中。相反,何时写回脏页由内核的守护进程决定,决定的依据是系统负载和用来限制在系统失败事件中的数据损失的配置参数。因此,如果只修改了一页中的一个字节,当修改被写回到文件中时,整个页都会被写回
如果共享映射中的页已修改,那么可以调用msync将该页冲洗到被映射的文件中。msync函数类似于fsync,但作用于存储映射区
1 |
|
如果映射是私有的,那么不修改被映射的文件。与其他存储映射函数一样,地址必须与页边界对齐
flags参数使我们对如何冲洗存储区有某种程度的控制。可以指定MS_ASYNC标志来简单的调试要写的页。如果希望在返回之前等待写操作完成,则可指定MS_SYNC标志。一定要指定两个标志中的一个
MS_INVALIDATE是一个可选标志,允许我们通知操作系统丢弃那些与底层存储器没有同步的页。若使用了此标志,某些实现将丢弃指定范围中的所有页,但这种行为并不是必需的
当进程终止时,会自动解除存储映射区的映射,或者直接调用munmap函数也可以解除映射区。关闭映射存储区时使用的文件描述符并不解除映射区
1 |
|
munmap并不影响被映射的对象,也就是说,调用munmap并不会使映射区的内容写到磁盘文件上。对于MAP_SHARED区磁盘文件的更新,会在我们将数据写到存储映射区后的某个时刻,按内核虚拟存储算法自动进行。在存储区解除映射后对MAP_PRIVATE存储区的修改会被丢弃
可以使用mmap和memcpy来读取或写入文件,与mmap和memcpy相比,read和write执行了更多的系统调用,并做了更多的复制。read和write函数将数据从内核缓存区中复制到应用缓冲区(read),然后再把数据从应用缓冲区复制到内核缓冲区(write)。而mmap和memcpy则直接把数据从映射到地址空间的一个内核缓冲区复制到另一个内核缓冲区。当引用尚不存在的内存页时,这样的复制过程就会作为处理页错误的结果而出现(每次错页读发生一次错误,每次错页写发生一次错误)。如果系统调用和额外的复制操作的开销和页错误的开销不同,那么这两种方法中就会有一种比另一种表现更好
第十五章 进程间通信
管道
管道是UNIX系统IPC(InterProcess Communication,进程间通信)的最古老形式,所有UNIX系统都提供此种通信机制。管道有以下两种局限性
- 历史上,它们是半双工的(即数据只能在一个方向上流动)。现在,某些系统提供全双工管道,但是为了最佳的可移植性,我们决不应预先假定系统支持全双工管道
- 管道只能在具有公共祖先的两个进程之间使用。通常,一个管道由一个进程创建,在进程调用fork之后,这个管道就能在父进程和子进程之间使用了
FIFO没有第二种局限性,UNIX系统域套接字没有这两种局限性
尽管有这两种局限性,半双工管道仍是最常用的IPC形式。每当在管道中键入一个命令序列,让shell执行时,shell都会为每一条命令单独创建一个进程,然后用管道将前一条命令进程的标准输出与后一条命令的标准输入相连接
管道是通过调用pipe函数创建的
1 |
|
经由参数fd返回的两个文件描述符:fd[0]为读而打开,fd[1]为写而打开。fd[1]的输出是fd[0]的输入
fstat函数对个管道的每一端都返回一个FIFO类型的文件描述符。可以用S_ISFIFO宏来测试管道
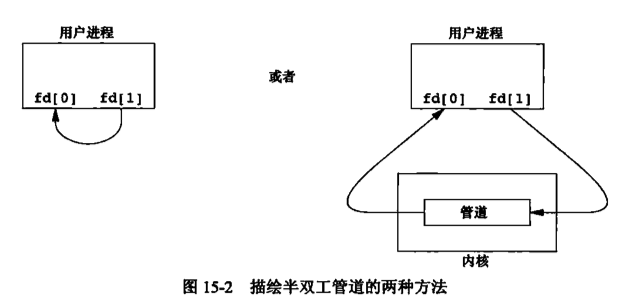
单个进程中的管道几乎没有什么用处。通常进程会先调用pipe,接着调用fork从而创建父进程到子进程的IPC通道,反之亦然。
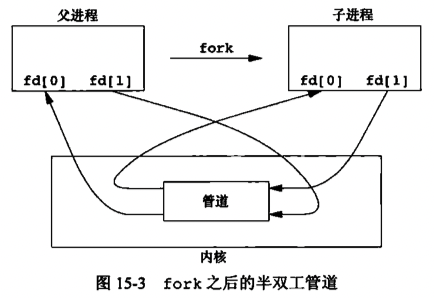
fork之后做什么取决于我们想要的数据流的方向,对于从父进程到子进程的管道,父进程关闭管道的读端,子进程关闭写端。反之亦然。
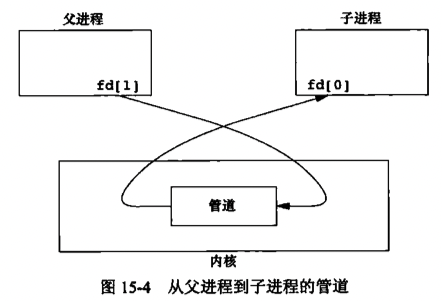
当管道的一端被关闭后,下列两条规则起作用
- 当读(read)一个写端已被关闭的管道时,在所有的数据都被读取后,read返回0,表示文件结束(从技术上来讲,如果管道的写端还有检查,就不会产生文件的结束。可以复制一个管道的描述符,使得有多个进程对它具有写打开文件描述符。但是通常一个管道只有一个读进程和一个写进程。下一节介绍FIFO时,会看到对于单个的FIFO常常有多个写进程)
- 如果写(write)一个读端已被关闭的管道,则产生信号SIGPIPE。如果忽略该信号或者捕捉该信号并从其处理程序返回,则write返回-1,errno设置为EPIPE
在写管道(或FIFO时),常量PIPE_BUF规定了内核的管道缓冲区大小。如果对管道调用write,而且要求写的字节数小于等于PIPE_BUF,则此操作不会与其他进程对同一管道(或FIFO)的write操作操作交叉进行。但是若有多个进程同时写一个管道(或FIFO),而且我们要求写的字节数超过PIPE_BUF,那么我们所写的数据可能会与其他进程所写的数据相互交叉。用pathconf或fpathconf函数可以确定PIPE_BUF的值
函数popen和pclose
常见的操作是创建一个连接到另一个进程的管道,然后读其输出或向其输入端发送数据,为此标准IO库提供了两个函数popen和pclose。这两个函数实现的操作是:创建一个管道,fork一个子进程,关闭未使用的管道端,执行一个shell运行命令,然后等待命令终止。
1 |
|
函数popen先执行fork然后调用exec执行cmdstring,并且返回一个标准IO文件指针。如果type是r,则文件指针连接到cmdstring的标准输出。如果type是w,则文件指针连接到cmdstring的标准输入

pclose函数关闭标准IO流,等待命令终止,然后返回shell的终止状态。如果shell不能被执行,则pclose返回的终止状态与shell已执行exit(127)一样。
popen决不应由设置用户ID或设置组ID程序调用。
FIFO
FIFO有时被称为命名管道。未命名的管道只能在两个相关的进程之间使用,而这两个相关的进程还要有一个共同的创建了它们的祖先进程。但是通过FIFO不相关的进程也能交换数据
FIFO是一种文件类型,可以通过stat结构的st_mode成员来确定是否是FIFO类型
创建FIFO类似于创建文件。确实,FIFO的路径名存在于文件系统中
1 |
|
mode参数与open函数中的mode参数说明相同。新FIFO的用户和组的所有权规则与文件相同
mkfifoat函数和mkfifo函数相似,但是mkfifoat函数可以被用来在fd文件描述符表示的目录的相关位置创建一个FIFO。与其他*at函数类似
当我们用mkfifo或mkfifoat创建FIFO时,需要用open来打开它。确实,正常的文件IO函数(如close、read、write和unlink)都可以在FIFO上工作
当open一个FIFO时,非阻塞标志(O_NONBLOCK)会产生下列影响
- 在一般情况下(没有指定非阻塞标志),只读open要阻塞到某个其他进程为写而打开这个FIFO为止。类似的,只写open要阻塞到某个其他进程为读而打开它为止
- 如果指定了非阻塞标志,则只读open立即返回。但是,如果没有进程为读而打开一个FIFO,那么只写open将返回-1,并将errno设置为ENXIO
类似于管道,若一个write一个尚无进程为读而打开的FIFO,则产生信号SIGPIPE。若某个FIFO的最后一个写进程关闭了该FIFO,则将为该FIFO的读进程产生一个文件结束标志
一个给定的FIFO有多个写进程是常见的。这就意味着,如果不希望多个进程所写的数据交叉,则必须考虑原子写操作。和管道一样,常量PIPE_BUF说明了可被原子的写到FIFO的最大数据量
FIFO有以下两种用途
- shell命令使用FIFO将数据从一条管道传送到另一条时,无需创建中间临时文件
- 客户进程-服务器进程应用程序中,FIFO用作汇聚点,在客户进程和服务器进程二者之间传递数据
XSI IPC
有3种称作XSI IPC的IPC:消息队列、信号量以及共享存储器。他们之间有很多相似之处。
标识符和键
每个内核中的IPC结构(消息队列、信号量和共享存储段)都用一个非负整数的标识符(identifier)加以引用。与文件描述符不同,IPC标识符不是小的整数。当一个IPC结构被创建,然后又被删除时,与这种结构相关的标识符连续加1,直到达到一个整型数的最大值,然后又回转到0
标识符是IPC对象的内部名。为使多个合作进程能够在同一IPC对象上汇聚,需要提供一个外部命名方案。为此每个IPC对象都与一个键(key)相关联,将这个键作为该对象的外部名
无论何时创建IPC结构(通过调用msgget、semget或shmget创建),都应指定一个键。这个键的数据类型是基本系统数据类型key_t,通常在头文件<sys/types.h>中被定义为长整型。这个键由内核变换成标识符
可以使用ftok函数将路径名和项目ID变换成一个键
XSI IPC有一个ipc_perm结构。该结构规定了权限和所有者。创建IPC结构时,对所有字段都赋值。以后可以调用msgctl、semctl或shmctl修改uid、gid和mode字段(调用进程必须是IPC结构的创建者或超级用户)
优点和缺点
XSI IPC的一个基本问题是:IPC结构是在系统范围内起作用的,没有引用计数。例如,如果进程创建了一个消息队列、并且在该队列中放入了几则消息,然后终止,那么该消息队列及其内容不会被删除。它们会一直留在系统中直至发生下列动作为止:由某个进程调用msgrcv或msgctl读消息或删除消息队列;当某个进程执行ipcrm命令删除消息队列;或正在自举的系统删除消息队列。将此与管道相比,当最后一个引用管道的进程终止时,管道就被完全的删除了。对于FIFO而言,在最后一个引用FIFO的进程终止时,虽然FIFO的名字仍保留在系统中,直至被显式的删除,但是留在FIFO中的数据已被删除了
XSI IPC的另一个问题是:这些IPC结构在文件系统中没有名字。为了支持这些IPC对象,内核中增加了十几个全新的系统调用(msgget、semop、shmat等)。增加了两个命令ipcs和ipcrm
其不使用文件描述符,不能对它们使用多路转接IO函数(select等)。这使得它很难一次使用一个以上这样的机构,或者在文件或设备IO中使用这样的IPC结构。
消息队列是可靠的,流控制的以及面向记录的;它们可以用非先进先出次序处理
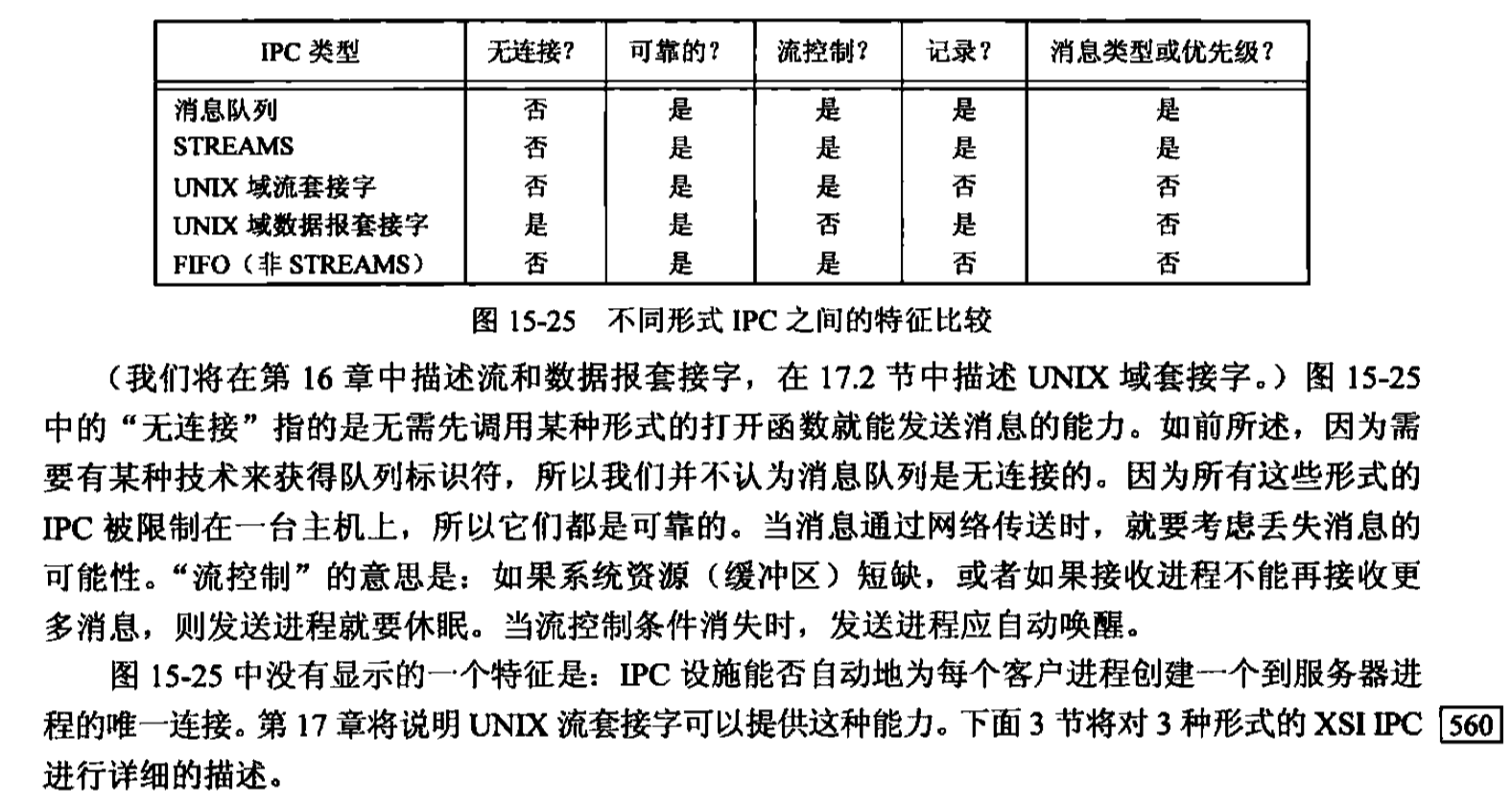
消息队列
消息队列是消息的链接表,存储在内核中,由消息队列标识符标识。
msgget用于创建一个新队列或打开一个现有队列。msgsnd将新消息添加到队列尾端。每个消息包含一个正的长整型类型的字段、一个非负的长度以及实际数据字节数(对应于长度),所有这些都在将消息添加到队列时,传送给msgsnd。msgrcv用于从队列中取消息。我们并不一定要以先进先出次序取消息,也可以按照消息的类型字段取消息
消息队列有一些限制
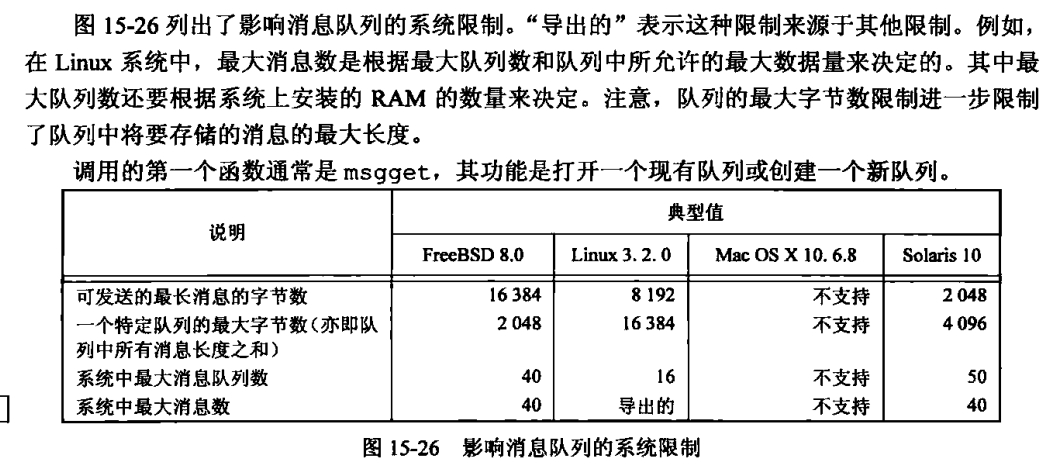
对删除消息队列的处理不是很完善。因为每个消息队列没有维护引用计数(打开文件有这种计数),所以在队列被删除以后,仍在使用这一队列的进程在下次对队列进行操作时会出错返回。信号量也以同样的方式处理其删除。相反,删除一个文件时,要等到使用该文件的最后一个进程关闭了它的文件描述符以后,才能删除文件中的内容
消息队列在新的应用程序中不应当再使用它们。因为消息队列与其他形式的IPC在速度方面已经没有什么差别了。但其存在一些问题
信号量
信号量与已经介绍过的IPC(管道、FIFO以及消息队列)不同。它是一个计数器,用于为多个进程提供对共享数据对象的访问
为了获得共享资源,进程需要执行下列操作
- 测试控制该资源的信号量
- 若此信号量的值为正,则进程可以使用该资源。在这种情况下,进程会将信号量值减1,表示它使用了一个资源单位
- 否则,若此信号量的值为0,则进程进入休眠状态,直至信号量值大于0。进程被唤醒后,它返回至步骤1
当进程不再使用由一个信号控制的共享资源时,该信号量值增1。如果有进程正在休眠等待此信号量,则唤醒它们。为了正确的实现信号量,信号量值的测试以及减1操作应当是原子操作。为此信号量通常是在内核中实现的
常用的信号量形式被称为二元信号量(binary semaphore)。他控制单个资源,其初始值为1。但是一般而言,信号量的初值可以是任意一个正值,该值表明有多少个共享资源单位可供共享应用
遗憾的是XSI信号量与此相比要复杂的多。
- 信号量并非是单个非负值,而必须定义为含有一个或多个信号量值的集合。当创建信号量时,要指定集合中信号量值的数量
- 信号量的创建(semget)是独立于它的初始化(semctl)的。这是一个致命的缺点,因为不能原子的创建一个信号量集合,并且对该集合中的各个信号量赋初值
- 即使没有进程正在使用各种形式的XSI IPC,他们仍然是存在的。有的程序终止时并没有释放已经 分配给它的信号量,所以我们不得不为这种程序担心。undo功能可以处理这种情况
信号量也有系统限制
信号量、互斥锁和记录锁有时可以实现相同的功能,如果信号不需要所有复杂的功能,可以使用互斥锁或记录锁来替代
共享存储
共享存储允许两个或多个进程共享一个给定的存储区。因为数据不需要再客户进程和服务器进程之间复制,所以这是最快的一种IPC。使用共享存储时唯一要掌握的窍门是,再多个进程之间同步访问一个给定的存储区。通常,可以用信号量同步共享存储访问(也可以用记录锁或互斥量代替)
共享存储有一定的系统限制
mmap也可以实现共享存储,但mmap需要有相关的文件关联(但利用mmap也可以实现匿名内存映射)
POSIX信号量
POSIX信号量接口意在解决XSI信号量接口的几个缺陷
- 相比于XSI接口,POSIX信号量接口考虑到了更高性能的实现
- POSIX信号量接口使用更简单:没有信号量集,在熟悉的文件系统操作后一些接口被模式化了。尽管没有要求一定要在文件系统中实现,但是一些系统的确是这么实现的
- POSIX信号量在删除时表现更完美。使用POSIX信号量时,操作能继续正常工作直到该信号量的最后一次引用被释放
POSIX信号量有两种形式:命名的和未命名的。它们的差异在于创建和销毁的形式上,其他工作方式一样。未命名的信号量只存在于内存中,并要求能使用信号量的进程必须可以访问内存。这意味着它们只能应用在同一进程中的线程,或者不同进程中已经映射相同内存内容到它们的地址空间中的线程。相反,命名信号量可以通过名字访问,因此可以被任何已知它们名字的进程中的线程使用
总结
经过分别消息队列与全双工管道的时间以及信号量与记录锁的事件进行比较,提出下列建议:要学会使用管道和FIFO,因为这两种基本技术仍可高效的应用于大量的应用程序。在新的应用程序中,要尽可能避免使用消息队列以及信号量,而应当考虑全双工管道和记录锁,它们使用起来会简单得多。共享存储仍然有它的用途,虽然通过mmap函数也能提供同样的功能

